文章
BabyAI Text 的RL&OPD总结
很多关于持续学习的讨论,都集中在模型如何在一个任务中越学越好,同时还能保持自己的通用能力。相比于在codind中探索数小时才能完成的任务,BabyAI Text是一个规模更小,但非常依赖空间推理能力且需要较长步骤才能完成的任务,同时对当前流行的模型足够陌生,可以避免模型在训练中找到捷径。
任务环境:
BabyAI Text 可以理解成 BabyAI 单房间任务的文字版本。模型每一步只能调用6个固定动作工具:转向(左右)、前进、拾取、放下、开门;环境会返回新的文字 observation,模型需要根据任务目标和新 observation 去推测任务完成的条件以及每个工具的作用。其任务特征主要为:
- 需要长程推理,任务需要十几步甚至二十几步才能完成
- 模型自身探索成功率低,但action space小,容易总结出规律
相比于数学、代码等任务,babyai并不是一个知识密集的任务,但它需要Agent从历史行为中总结出规律并通过训练将规则内化到模型权重中。我们的目的是探索LLM的自适应学习,因此原则上不去做rubrics reward:例如检测N步内是否仍原地打转,或pick up的钥匙是否对应门的颜色等等。
train 和 eval都是用BabyAI-MixedTrainLocal设置不同seed生成,未设置unseen任务eval。
(作为对照:glm-5.1 Agentic形式成功率为0.52)。
| task type | count |
|---|---|
| go_to | 5 |
| go_to_after_pick_up | 9 |
| open | 11 |
| pick_up | 11 |
| pick_up_then_go_to | 6 |
| put_next_to | 8 |
总结版
| 路线 | 核心设置 | best eval success rate | 说明 |
|---|---|---|---|
baseline | 原始qwen3-14b | 0.26 | |
v1.1 | episode-level GRPO,interleaved thinking | 0.30 | log_probs 崩,后期 format 崩 |
v1.2 | 调整任务采样比例,丢弃组内无方差 group | 0.36 | 格式好一些,但困难任务仍然学不会 |
v1.3 | 在初期剔除负优势样本 | 0.42 | 在恢复正负优势样本训练后,80~140steps左右仍然格式崩坏 |
v2.1 | outcome reward + 0.5 x turn level LLM judge | 0.52 | outcome reward的噪声较大 |
v2.2.2 | turn-level RL + LLM judge | 0.74 | 效果明显提升,但需要额外 judge 成本,且减少了模型的思考长度 |
v3.1.1 | 长推理 teacher 的 OPD | 0.5 | 迅速将输出长度拉长,导致格式准确率大幅下降,并且长输出rollout速度慢,训练十分缓慢 |
v3.1.2 | OPD基础上增加format reward | 0.44 | |
v3.1.3 | 只蒸馏前30% token | 0.48 | 相比v3.1.1,效果接近,生成长度在被拉长后迅速降低,训练速度提升5倍。 |
v3.2 | RL teacher(v2.2.2) 的 OPD | 0.78 | 训练非常顺,最终超过 teacher,但同样减少了模型的思考长度 |
1. RL baseline#
初始prompt:任务目标+初始环境observation
messages格式 interleaved thinking:
<system>
<user>
<assistant_think>
<assistant_tool_calls>
<user_tool_response>
<assistant_think>
<assistant_tool_calls>
<user_tool_response>reward 任务成功=1,任务失败=-1,format正确0.5,错误-0.5
训练模型 qwen3-14b,grpo训练,group=8,loss mask 掉 tool_response
v1.1 baseline GRPO#
训练到第60步时,log_probs崩,80步format崩。观察rollout的采样成功率,open和put_next_to成功率都很低,尤其是put_next_to从初始的2.78%成功率跌至0.3%左右。
best eval success_rate(60 step) = 0.3
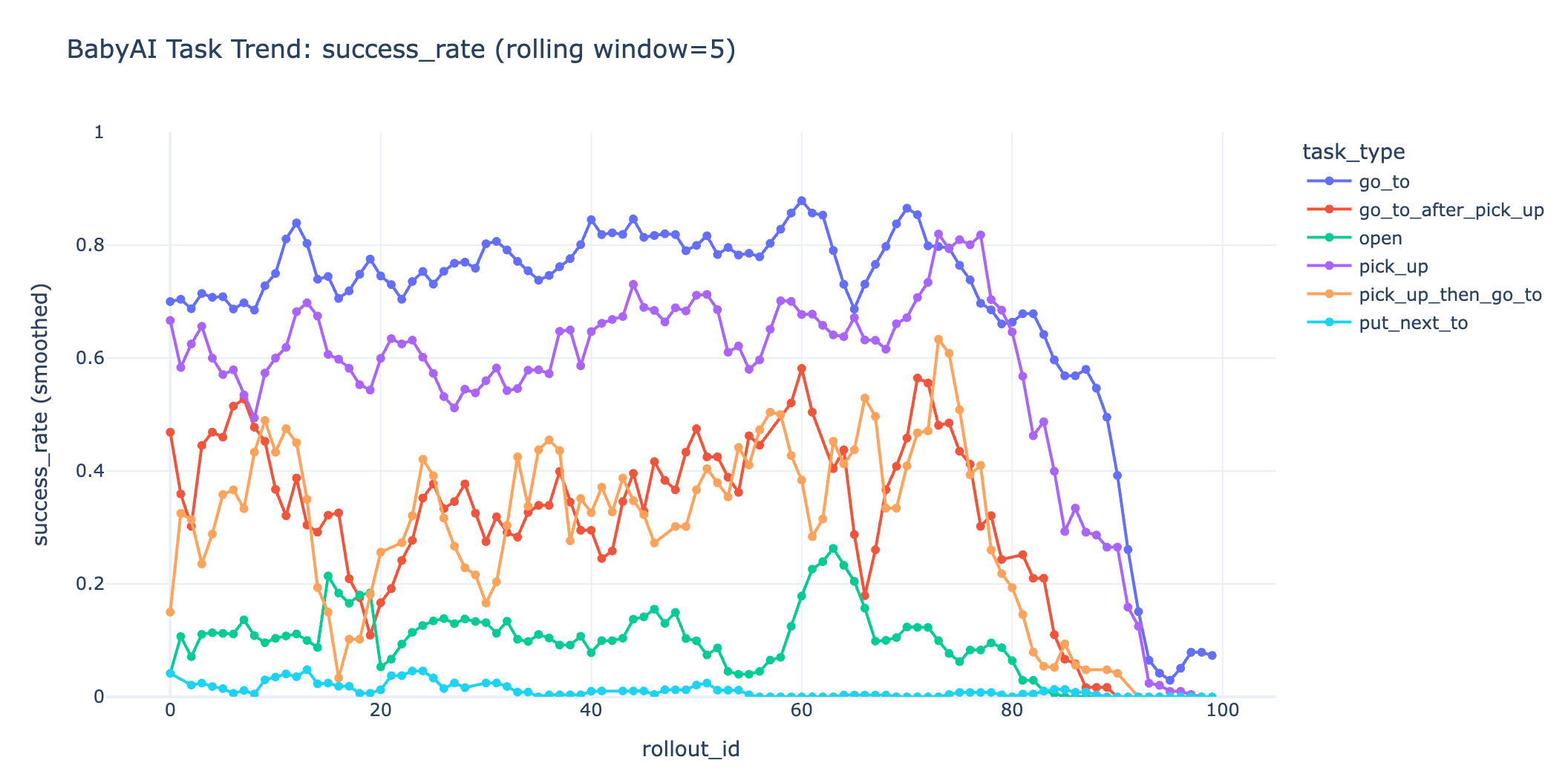
v1.2 提高难任务的采样比例,同时保证组内方差#
参考DAPO:采样时,将各任务的比例保持一致,同时增大采样,丢弃组内没有方差的group。这组实验比v1.1训练提高了稳定性,但依然在第120步时log_probs骤降,第130步左右format崩。
best eval sr(60 step) = 0.36
rollout成功率,最差的put_next_to,基本上只保持着未丢弃组的成功率,大约12.5%~15%。
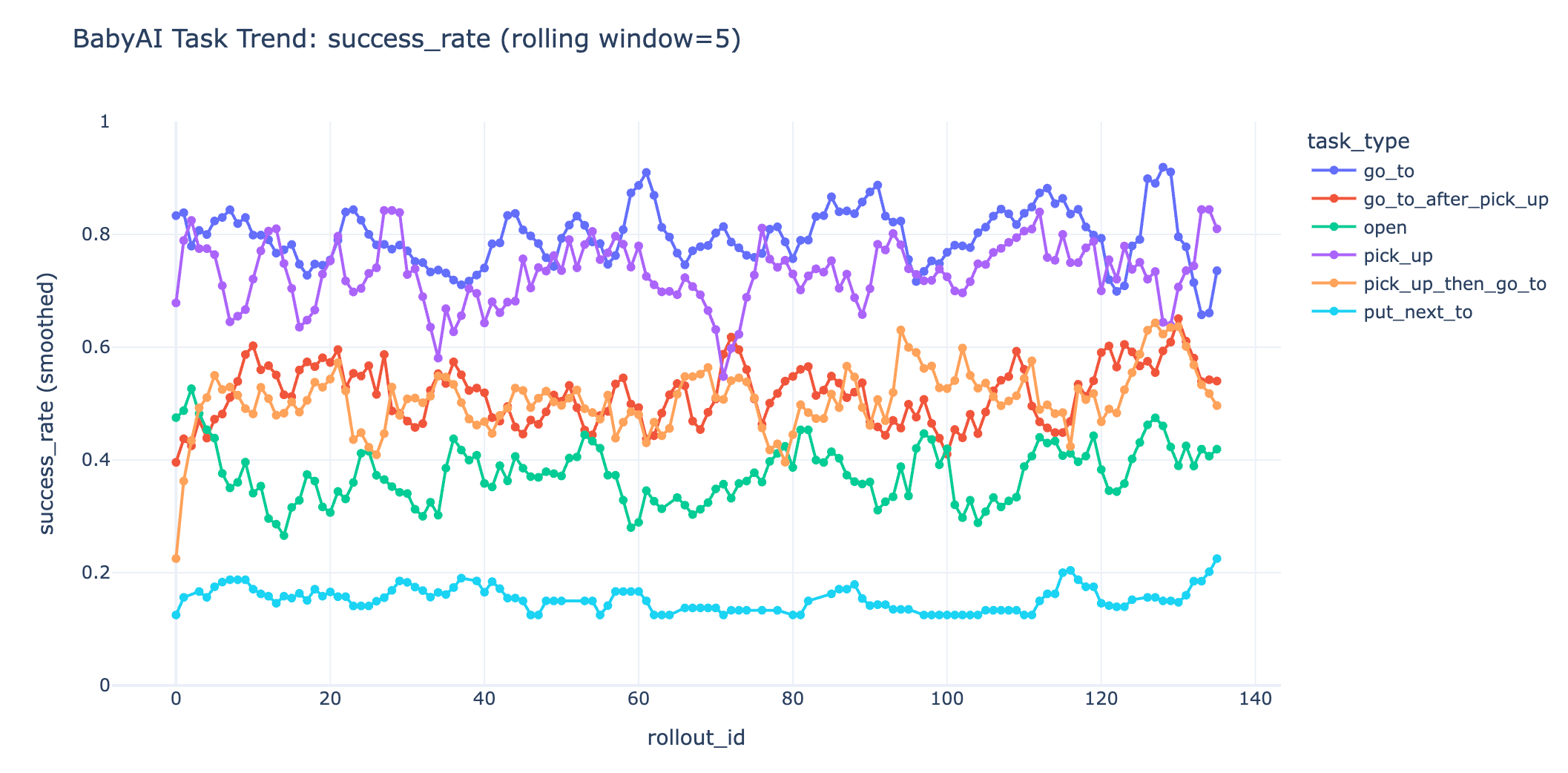
两组实验对于难样本的训练几乎都没有什么提升,最终都崩在format失败。
qwen3作为思考模型,初期会生成较长的思考过程,但都无法有效的提高采样成功率,并且作为一个平均15步以上的任务,中间的正确步骤会因为最终的未完成被错误惩罚,从而导致正向信号太弱,最终都训练崩溃。
一个典型的探索失败的例子:
assistant
<think>
Okay, let's tackle this step by step. First, I need to pick up the red box, which is 1 step left and 1 step forward.
...
The red box is 1 step left and 1 step forward from my current position.
...
If the red box is to my left and forward, maybe I need to turn left once, then move forward.
...
So, first action: turn left.
</think>
<tool_call>
{"name": "turn_left", "arguments": {}}
</tool_call>
user
<tool_response>
You see a wall 5 steps forward
You see a wall 1 step left
You see a yellow key 1 step right and 2 steps forward
You see a red box 1 step right and 1 step forward
...
</tool_response>
assistant
<think>
... the red box is now 1 step right and 1 step forward.
So if I turn right once, the red box would be directly in front.
Then I can move forward once to pick it up.
</think>
<tool_call>
{"name": "turn_right", "arguments": {}}
</tool_call>
user
<tool_response>
You see a wall 2 steps right
You see a purple key 1 step left and 4 steps forward
You see a red box 1 step left and 1 step forward
...
</tool_response>
assistant
<think>
... the red box is 1 step left and 1 step forward.
So next action: turn left, then go forward once to pick up the red box.
</think>
<tool_call>
{"name": "turn_left", "arguments": {}}
</tool_call>v1.3 动态课程学习#
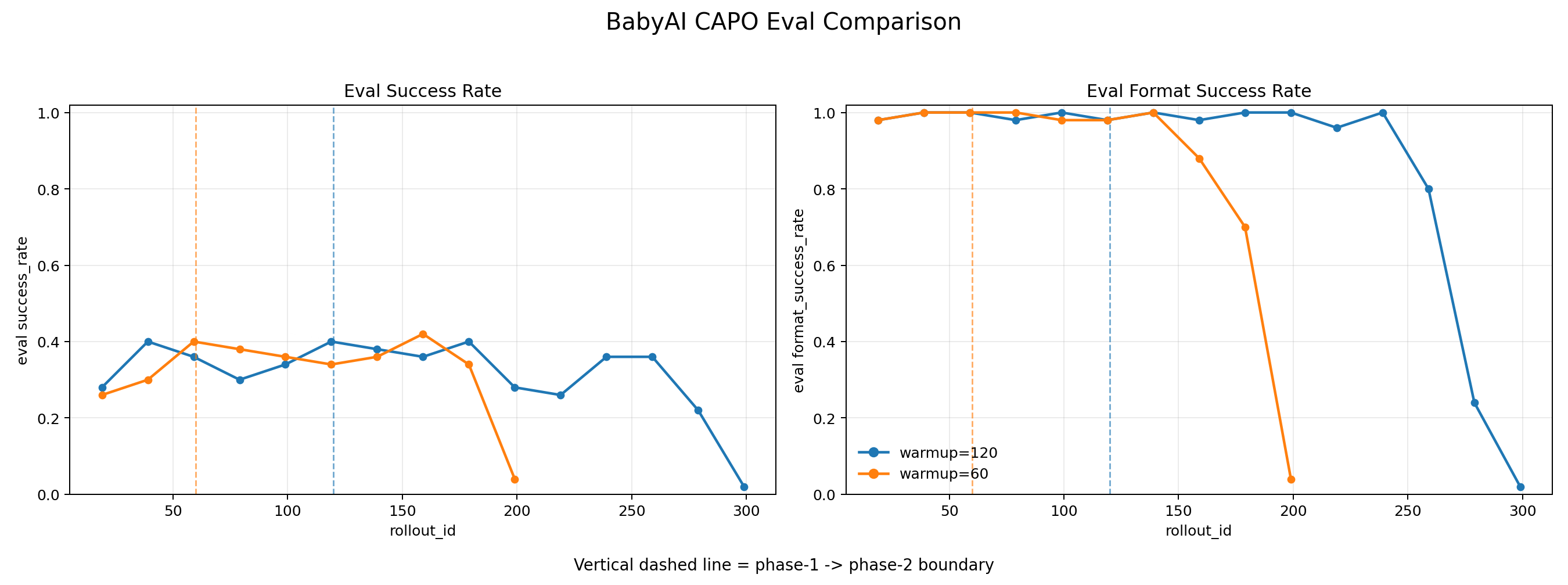
将任务从简单到难进行训练需要对任务数据的分布做调整,但由于探索的是模型自己的学习能力,还是需要尽量减少人工的处理。小米的 CAPO 提出在初期剔除负优势样本,只优化自己超出预期的表现,避免负优势样本的显著惩罚造成策略崩溃等问题。
分别尝试在60 steps和120 steps之前剔除负优势样本,两者都可以达到0.4左右的eval sr。尽管120steps没有带来更高的成功率,但它相比60steps,训练稳定程度更好。
2. turn level + LLM judge#
messages格式
<system>
<user>
- 10 history tool_calls & tool_response
<assistant_think>
<assistant_tool_calls>使用LLM根据完整的trajectory,对中间某一个step进行打分。打分的内容包括thinking、plan以及action的正确性。
由于LLM judge在这个任务上整体可以达到80%的人工打分程度,整体打分方差可控,为了减少glm-5.1的打分量,最终去掉GRPO中的baseline做基础尝试。将group设为1,每个trajectory随机抽取4个turn sample,对单个turn_sample进行训练,整体退化为PPO clip式的REINFORCE方法。
v2.1 保留outcome reward#
reward = 0.5 x orm + 0.5 x LLM judge reward + format reward
使用glm-5.1打分,best eval sr = 0.52
v2.2 仅保留LLM judge reward#
reward = LLM judge reward + format reward
| judge model | best eval sr | |
|---|---|---|
| v2.2.1 | glm-5 | 0.64(1000 step) |
| v2.2.2 | glm-5.1 | 0.74(820 step) |
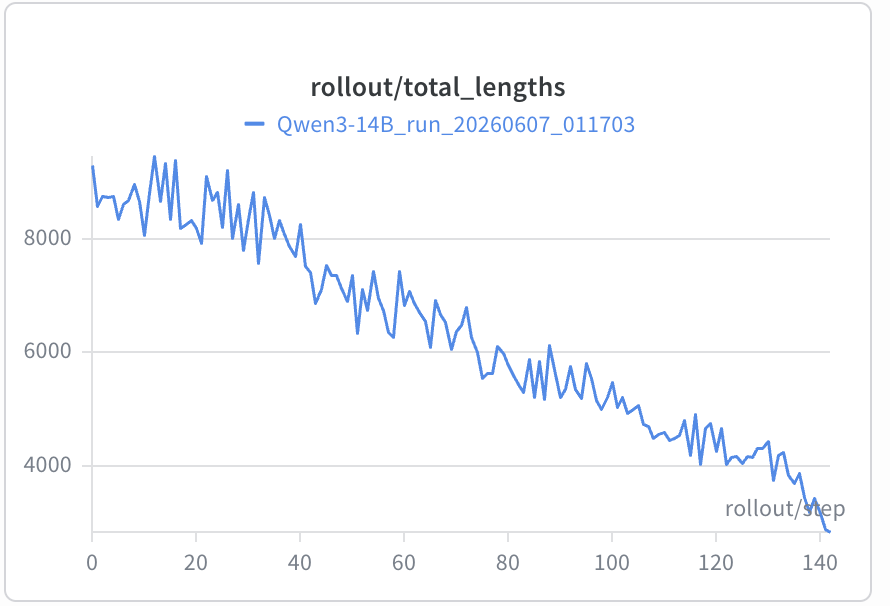
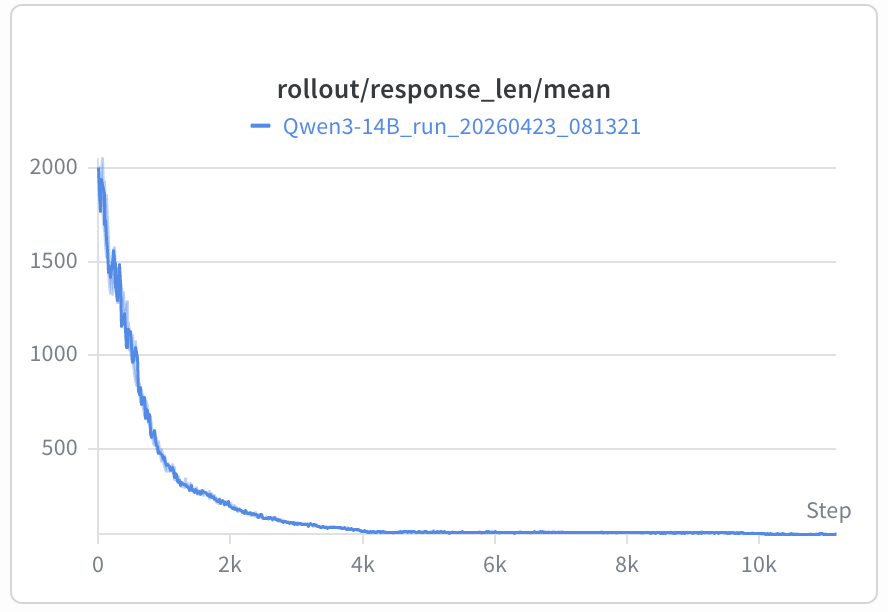
以v2.2.2为例,尽管在LLM judge中强调了对环境的判断、工具的理解进行打分,但随着训练的进行,response length从2000左右在400 step降到190左右(图中的step除以10是真实的step),最终稳定在50+。统计长度和LLM judge分数相关性为-0.31,最短20%的样本得分0.767,而最长20%的样本得分只有0.18。
通过case可以看出长推理更容易产生局部的错误,LLM从后续的fobservation中也更容易发现这类错误,从而打上低分,另外长输出也容易造成格式的不稳定,format reward也有扣分。这导致短输出整体上在LLM judge和format reward上都更稳定,随着训练进行,模型越来越倾向于短输出。这同时也从侧面表明这个任务并不需要复杂的推理,当对任务工具有了准确理解之后便能获得更高的准确率。
ORM的噪声#
为什么episode-level的训练只靠ORM无法成功。统计v2.2.2的rollout结果,在初期采样失败率44.76%的基础上,有38%的比例是LLM judge认为是ORM错误惩罚的。在episode-level的采样过程中,错误的比例会更高。
| 阶段 | 全部样本数 | 失败样本数 | 失败率 | P(judge>=0 | ORM<0) | P(judge>=0.5 | ORM<0) |
|---|---|---|---|---|---|
| 0-200 | 50,785 | 22,729 | 44.76% | 38.52% | 21.03% |
| 200-400 | 50,048 | 17,846 | 35.66% | 44.77% | 30.23% |
| 400-600 | 49,904 | 12,136 | 24.32% | 60.14% | 45.84% |
| 600-800 | 49,812 | 6,552 | 13.15% | 64.48% | 50.38% |
| 800-1000(best eval) | 65,988 | 5,700 | 8.64% | 68.09% | 55.00% |
在open和put_next_to两个低成功率任务上,orm贡献了整体30%+的错误惩罚。因此在v1中,仅靠ORM几乎无法使两个困难任务得到有效的提升。
| all | fail | P(j>=0 | ORM<0) | joint/all | fail_rate | |
|---|---|---|---|---|---|
| open | |||||
| 0-200 | 9439 | 7613 | 39.68% | 32.01% | 80.65% |
| 200-400 | 8566 | 5350 | 46.09% | 28.79% | 62.46% |
| put_next_to | |||||
| 0-200 | 5559 | 4654 | 40.80% | 34.16% | 83.72% |
| 200-400 | 4822 | 4312 | 55.33% | 49.48% | 89.42% |
v2.3 降低format reward#
v2.1和v2.2的ORM都有很强的格式错误惩罚,如果格式错误,就被认为整条轨迹失败,并且叠加format error,最终有-1.5的reward,这导致一旦有格式错误,中间的正确action也会被给予严厉的惩罚。
参考Self-Distilled Agentic Reinforcement Learning在ALFWorld的GRPO实现中,对格式错误十分温和,如果模型的输出无法被正确解析,使用last 30 tokens给env执行,同时给这个step -0.1的reward(正确完成任务reward=10)。
用Qwen3.5-4B复现了ALFWorld的结果,在unseen任务上可以达到0.79的sr。将这一设置应用在babyai中,以v2的基础上,去除LLM judge,设置max_turns=30,然而最终best_eval_sr=0.3(20 steps),后面越来越差。
3. On Policy Distillation#
v3.1 长推理的teacher#
使用glm-5.1生成数据进行SFT作为teacher。glm-5.1拥有很强的推理能力,通过设置working memory去激发对环境的推理能力。
prompt构造分为两阶段:
- 生成action
<system>
<user>
- last turn working memory
- 10 history messages
<assistant>
- action- 生成working memory
<system>
<user>
- last turn working memory
- 10 history messages
<assistant>
- working memoryworking memory的作用是为了提高模型对tools以及环境的理解,每当执行完一个action后,根据env observation进行反思推理,生成对环境的理解、后续策略。
glm-5.1在max_turns=30的情况下,使用这种方式可以达到0.92的准确率。以此生成sft数据,训练qwen3-14b作为teacher。训练完成后的teacher eval_sr=0.78。
teacher在memory环节,平均输出长度约为2700 tokens,action环节约470 tokens。
v3.1.1#
format error rate(think未闭合或tool json解析失败)在20 steps+时急速变差,后续有所降低,但仍稳定在0.4左右的错误率上。最终best eval sr=0.34,从rollout的sample来看,模型学会了尝试去建立坐标系,推理自身位置,但最终在推理结果的正确性和对<think>标记的控制失败。
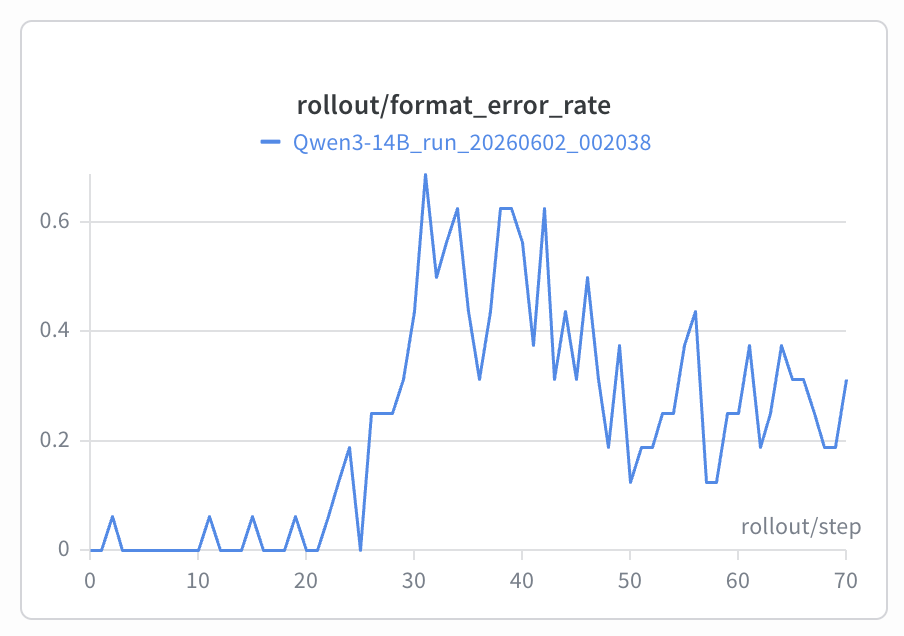
但如果观察reverse KL、teacher log probs,这些surrogate 指标都在改善。
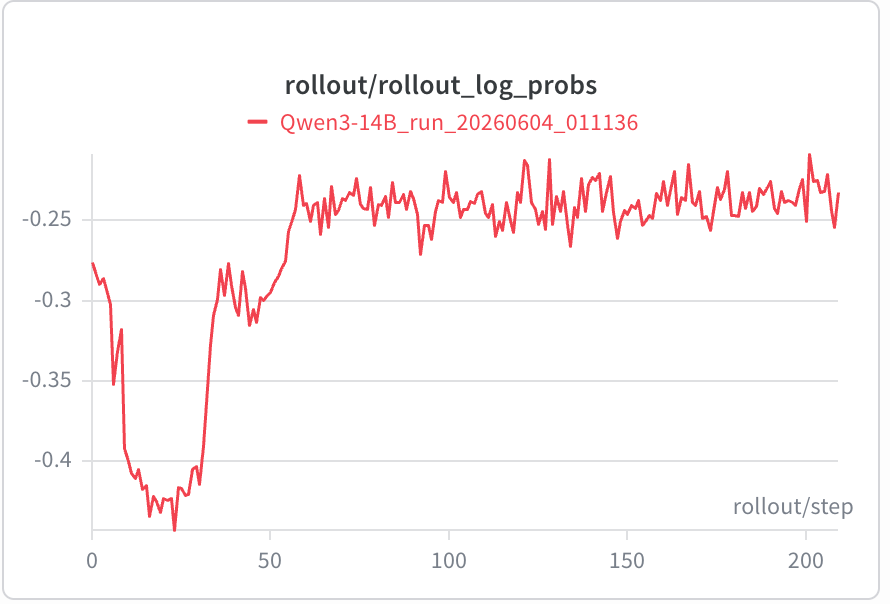
student rollout log probs随着response length的变长先降低再增长。
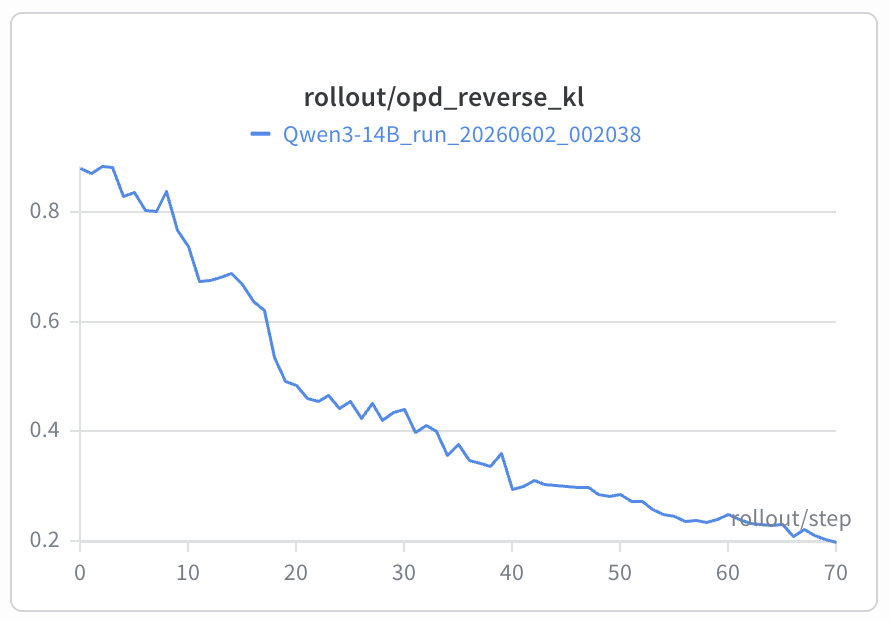
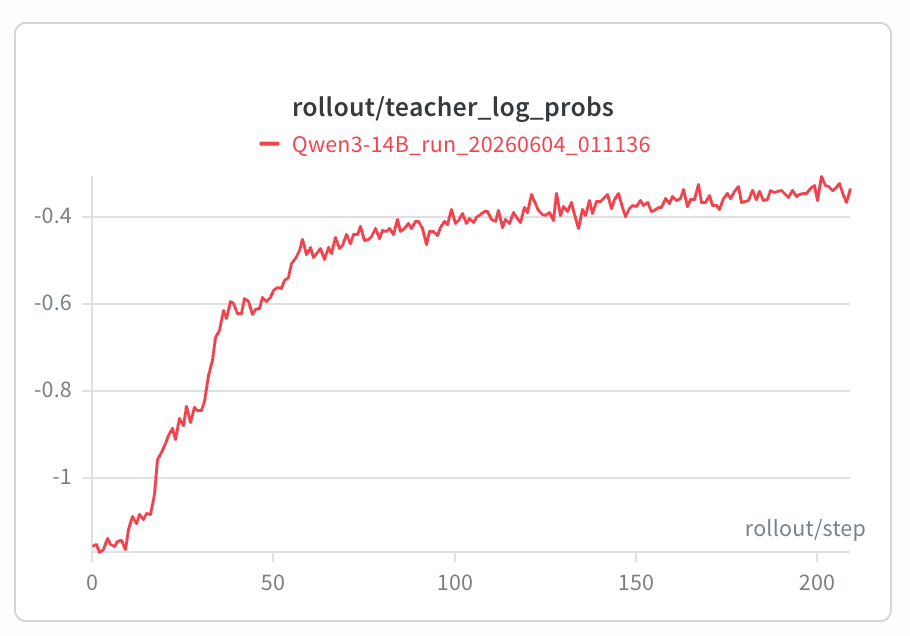
在《Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe》 中,作者也讨论了随着student prefix变长,teacher在该prefix上续写的答案准确率也逐渐降低,意味着随着上下文增加,teacher的指导信号也变得不可靠。采用相同的检测方法,取student 前80%prefix,让teacher续写,最终格式成功比例只有0.56,在response_length>4096的sample中,格式成功率甚至跌到了0.08,基本可以证明OPD在长文蒸馏中的缺陷。
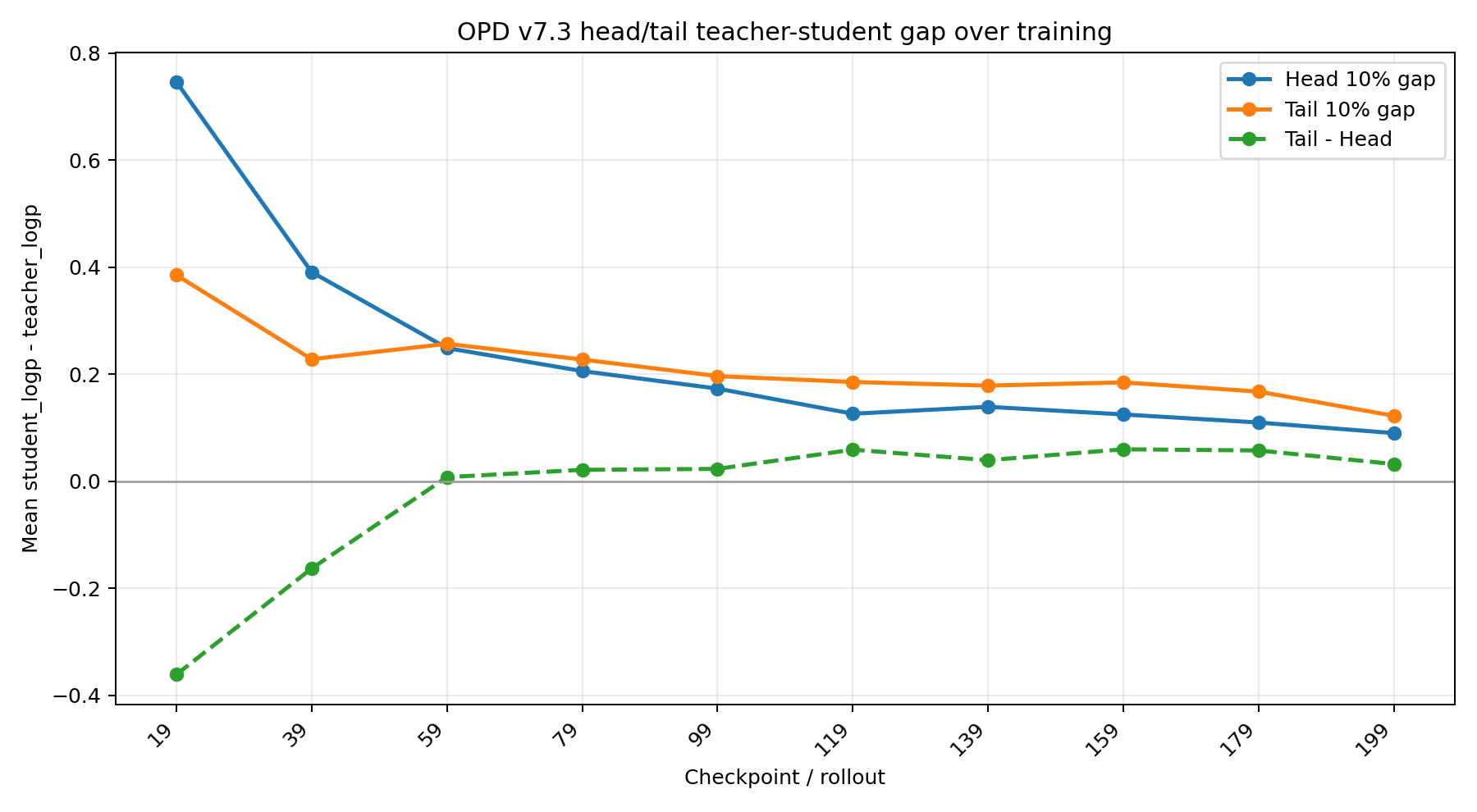
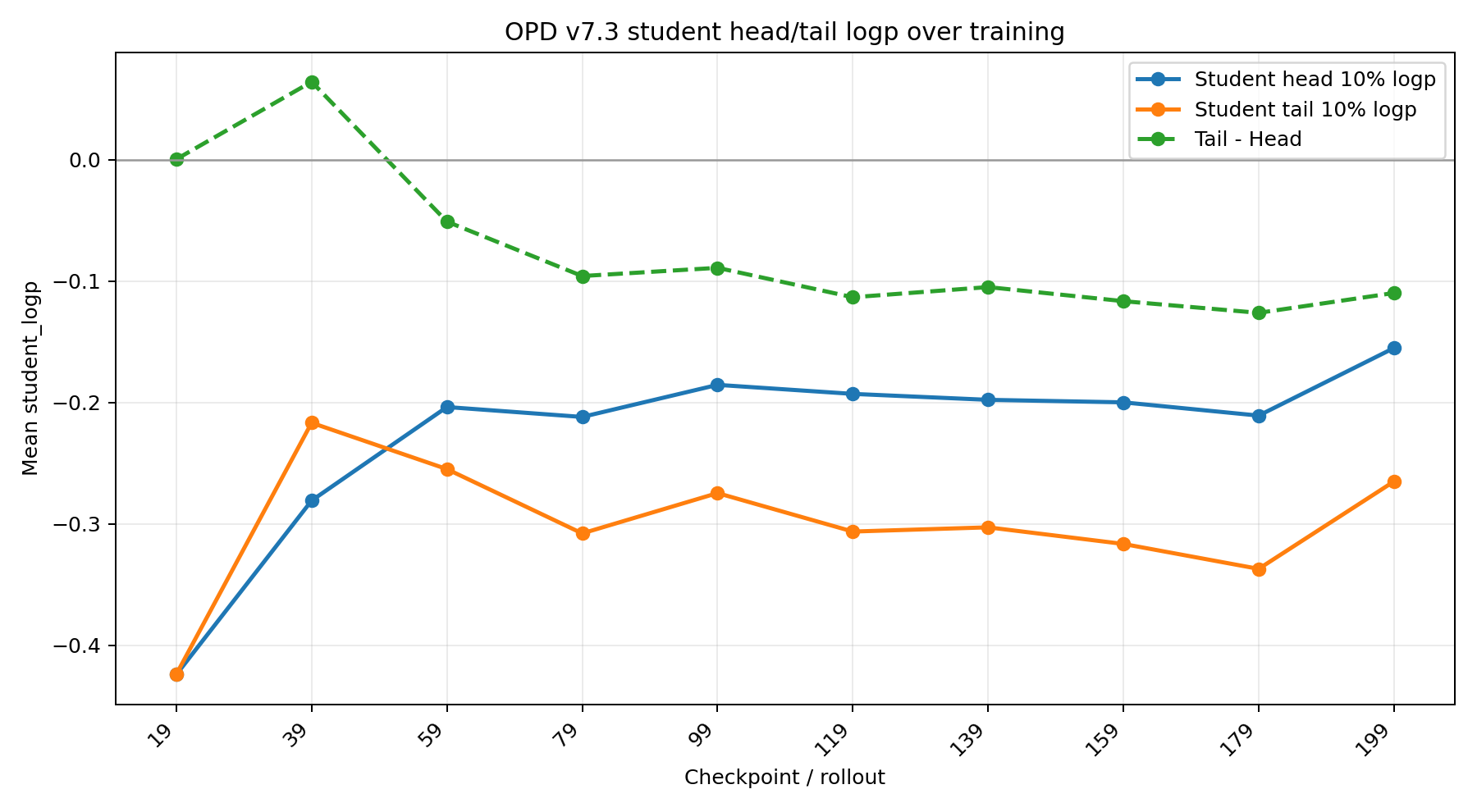
从左图可以看出,tail的teacher-student logp gap的的训练程度显著低于head部分,Student的logp(右图),也可以看出tail部分的自信程度显著低于head部分。
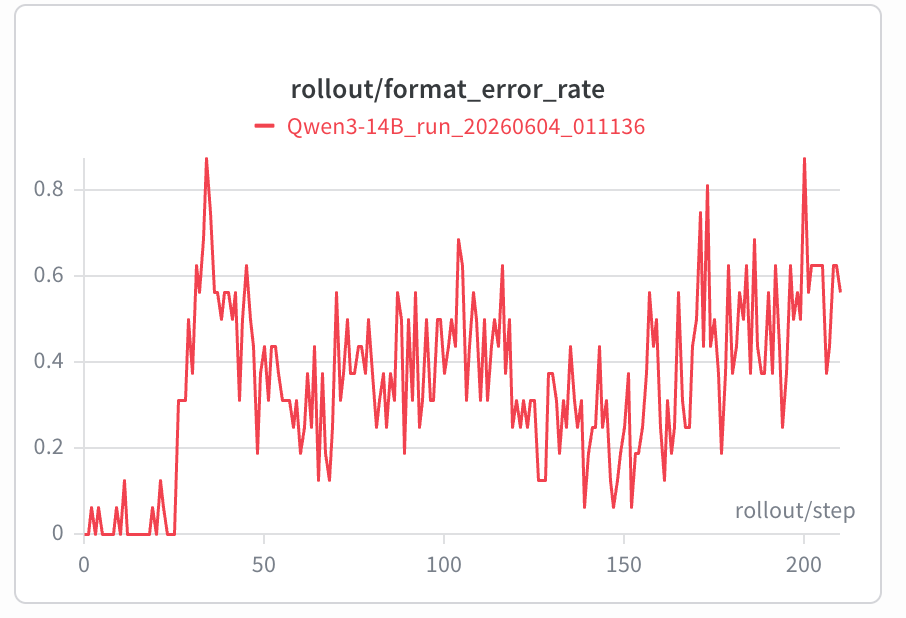
v3.1.2 增加format reward#
增加format reward,在初期format error仍暴涨,但后续能得到一些控制,最终best eval sr=0.44
- 随机抽样
100条样本(seed=0),取 student 输出前80%token 作为 prefix,拼到原始sample.prompt后交给 teacher继续生成,再用 visible-memory parser 检查重建后的完整输出是否格式通过。 - 结果:格式通过率
56 / 100 = 0.56,平均 prefix 长度3006.6tokens,平均完整 student 输出长度3758.7tokens。
如果只看超长 memory 样本(response_length >= 4096):
- 随机抽样
50条样本(seed=0),同样取 student 的80% prefix让 teacher 续写。 - 结果:格式通过率进一步降到
4 / 50 = 0.08,平均 prefix 长度6594.5tokens,平均完整 student 输出长度8243.6tokens。
这个结果说明:teacher 在中等长度的 student prefix 上还能部分“接住”,但一旦 student memory prefix 真的很长,teacher continuation 的格式稳定性会急剧恶化。表明模型本身在长输出的情况下对格式的保持就是脆弱的。
v3.1.3 只蒸馏前30% token#
很多OPD相关的论文都分析了对于student的长输出,后半部分对于teacher来说已经OOD,无法给出有效的指导。而靠前的token,一方面和teacher分布相似度较高,另一方面也主导这后续推理的方向,因此做一次只蒸馏前30%的简单尝试。
在steps=180的时候得到最佳eval sr=0.48。和全位置蒸馏的最大差别在于:
- 只蒸馏前30%时,平均输出长度很快收敛在1000左右,格式错误也随着长度回落而逐渐降低到10%以下
- 而全位置蒸馏会持续上升至4000左右,从轨迹内容来看,全蒸馏的student对于当前的state花费了非常长的思考但始终无法推理出正确路径,格式错误也始终维持在40%左右
v3.1.3 Top K词表蒸馏#
v3.2 短推理的teacher#
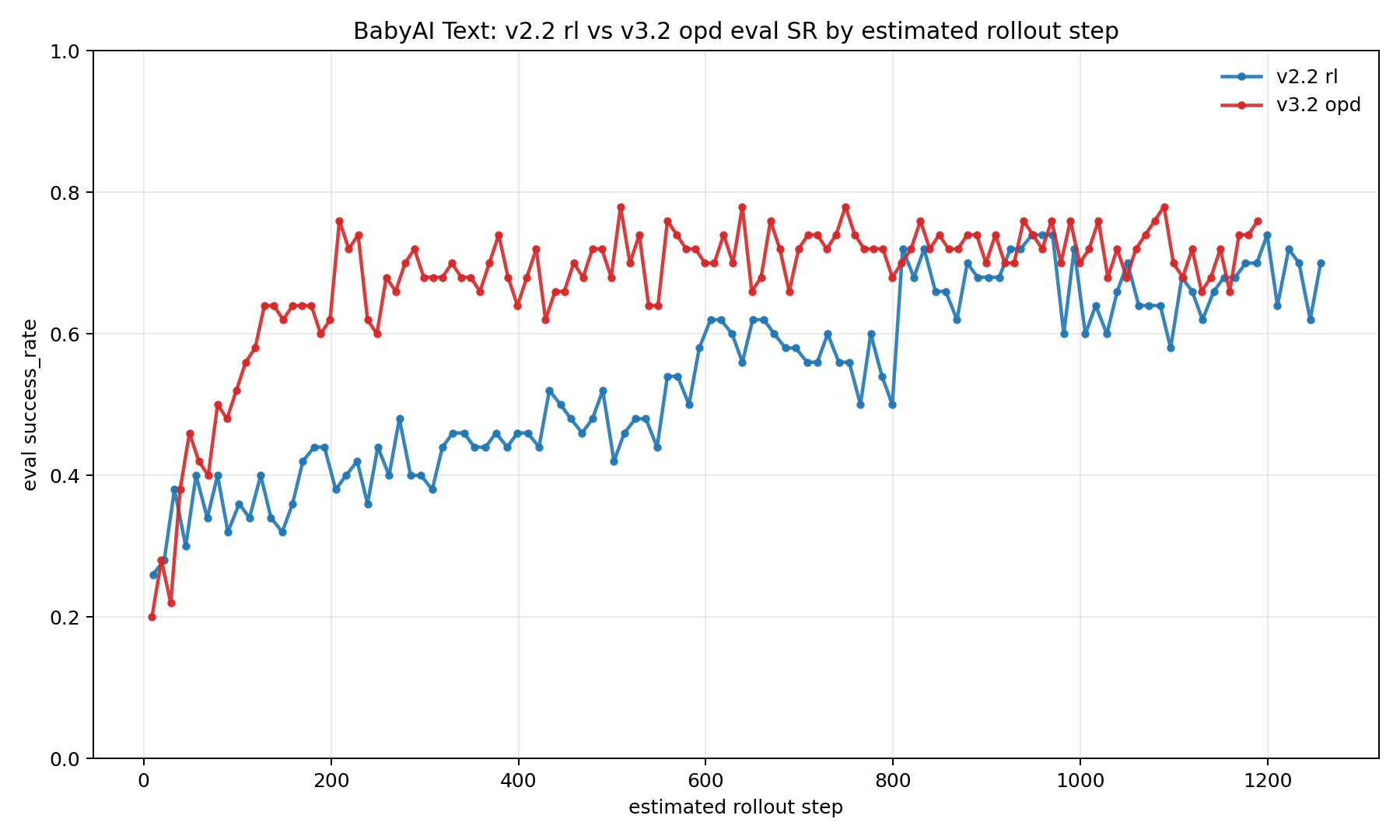
使用v2.2.2的模型作为teacher,v2.2.2的平均输出长度为50。从下图可以看出,对于这种每一轮都是短输出,opd的蒸馏效果非常好,token级的训练效率也很高,在200steps时就可以达到0.76左右。
4. 通用能力评估#
评估四个模型
- Qwen3-14B,baseline基础
- v2.2.2,经过LLM judge的RL模型,训练后thinking变短
- v3.1 teacher,经过glm-5.1长思考链的SFT模型,训练后thinking内容变长
- v3.2 student,v2.2.2作为teacher经过opd训练的模型,thinking也变短
指令遵循能力
| 模型 | IF-Eval | mean tokens | median | p95 |
|---|---|---|---|---|
| Qwen3-14B | 0.8965 | 952.3 | 659 | 2670 |
| v2.2.2 | 0.8965 | 624.4 | 403 | 1439 |
| v3.1 teacher | 0.8521 | 993.7 | 639 | 4117 |
| v3.2 student | 0.8983 | 654.3 | 398 | 1477 |
知识&中短推理(MMLU-Redux 2.0)
| 模型 | Micro | Macro | mean tokens | median | P95 |
|---|---|---|---|---|---|
| Qwen3-14B | 0.8994 | 0.8979 | 876.6 | 511 | 2624 |
| v2.2.2 | 0.8912 | 0.8894 | 448.7 | 292 | 1165 |
| v3.1 teacher | 0.8296 | 0.8283 | 945.8 | 429 | 2701 |
| v3.2 student | 0.8886 | 0.8869 | 403.0 | 286 | 948 |
知识&长推理(GPQA-Diamond)
| 模型 | Flexible | Strict | chemistry | biology | physics | invalid | mean tok | median | p95 |
|---|---|---|---|---|---|---|---|---|---|
| Qwen3-14B | 0.621 | 0.606 | 0.398 | 0.684 | 0.849 | 1 | 5039.3 | 4405.5 | 10929.5 |
| v2.2.2 | 0.586 | 0.586 | 0.419 | 0.632 | 0.756 | 1 | 2099.9 | 1076.5 | 6299.5 |
| v3.1 teacher | 0.586 | 0.475 | 0.333 | 0.632 | 0.814 | 8 | 13157.5 | 9713.0 | 32768.0 |
| v3.2 student | 0.581 | 0.556 | 0.387 | 0.736 | 0.756 | 0 | 1288.9 | 831.0 | 4647.5 |
- 对于指令遵循(IF-Eval),v3.1 teacher经过长思维链的sft之后,对指令遵循有明显的下降,RL和OPD则基本可以保持原模型的能力。
- 对于知识储备(MMLU-Redux 2.0),sft之后退化也显著高于RL和OPD
- 对于长推理,sft后的模型在physics这种精确的推理计算上,衰退较小。比较意外的是对于RL和OPD模型来说,在单一任务上的训练也能影响其他任务的推理长度,所有的任务上RL和OPD都比Qwen3-14B少了接近一半,这相当于改变了模型的推理模式。对于physics这类需要精确推理计算的,这样的变化仍然带来了不小的损失。而chemistry这类知识+推理的,则没有明显的变差。
5. Skill RL + Self On Policy Distillation#
上一节中可以看到,SFT、RL和OPD都会在不同维度损伤模型自身能力,而RL和OPD在知识储备上对原模型影响很小,如果能够提高student模型自身的采样成功率,则有可能保留模型自身的思考模式。
旗舰模型在BabyAI的成功率#
prompt形式:
working memory:显示输出一轮对环境/动作的理解,作为下一轮输出action时的历史输入
agentic: tool_calls/tool_response的形式,10轮history messages
context:working memory+10轮history
| max_turns | eval success rate | 备注 | |
|---|---|---|---|
| glm-5 | 20 | 0.26 | context组装 |
| glm-5 | 20 | 0.68 | 2轮分别生成memory、action |
| glm-5 | 20 | 0.38 | agentic |
| glm-5 | 20 | 0.34 | agentic+reasoing回放 |
| glm-5 | 30 | 0.76 | 2轮分别生成memory、action |
| glm-5.1 | 20 | 0.46 | context组装 |
| glm-5.1 | 20 | 0.52 | agentic |
| glm-5.1 | 20 | 0.6 | agentic+reasoing回放 |
| glm-5.1 | 20 | 0.8 | 2轮分别生成memory、action |
| glm-5.1 | 30 | 0.92 | 2轮分别生成memory、action |
| glm-5.1 | 20 | 0.44 | 单轮同时生成memory、action,这样的memory更像thinking过程,难以生成两轮生成时的环境分析和动作理解 |
单独生成working memory,模型被告知之后的action以memory为主,因此会触发更详细的分析