简介
围棋被誉为是人类的智力巅峰,在很长一段时间一直都是人工智能在棋类领域内最大的挑战。在所有具有完全信息的博弈游戏中,都有一个可以决定最优策略的价值函数,在每一个局面下,可以通过递归的搜索最优策略使得自己获得胜利(穷举所有可能的走法,找到最优的策略),也就是说只有决定了先后手,就决定了游戏的输赢。搜索序列个数大约是个,是搜索的宽度(在围棋中是每一个局面下所有合法的落子),是搜索的深度(双方棋手一共落子的步数)。大型棋类游戏中,国际象棋中的,,在围棋游戏中,,,在现有的计算条件是不可能完成的。可以通过两种方式来有效的减少搜索空间:
-
通过对局面的评估降低搜索深度,在搜索树中的某一节点时停止向下搜索,以当前的评估代替对子节点的评估,这在国际象棋、西洋棋等游戏中有着超越人类的效果,但在复杂的围棋中的效果并不好。
-
通过训练一个策略函数 (一个根据当前状态s输出落子策略的概率分布函数)来减少搜索宽度(舍去概率低的落子策略),这在西洋双陆棋等游戏中有超越类的表现,在围棋中只能达到业余爱好者的水平。
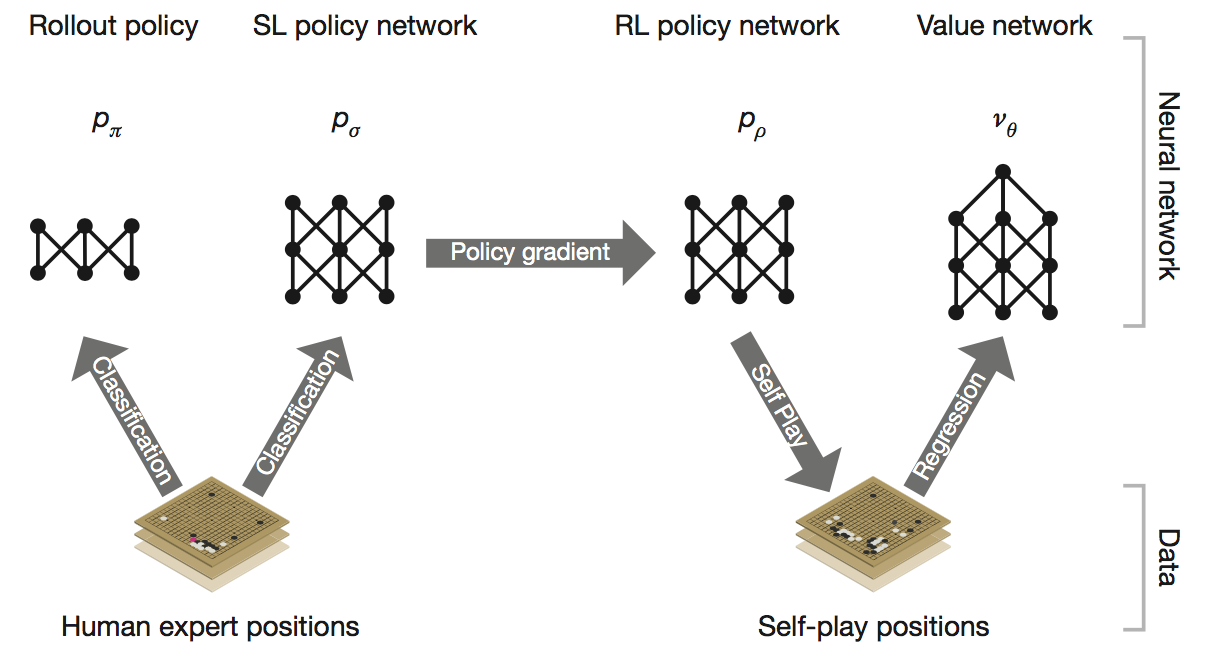
AlphaGO通过训练策略网络、估值网络以及构造蒙特卡洛搜索树(MCTS)来减少搜索的宽度和深度,整个训练分为三个步骤:1.根据人类棋局使用监督学习训练出策略网络(SL Policy)和一个快速落子的策略网络,使用更少的特征和神经元,能够快速地计算出落子策略;2.自我对局提升策略网络,使用初始化,使用增强学习的方法训练的(RL Policy);3.最后利用自我对局训练一个估值网络用来预测在当前局面下,估计白胜还是黑胜。
训练过程
Supervised learning of policy network
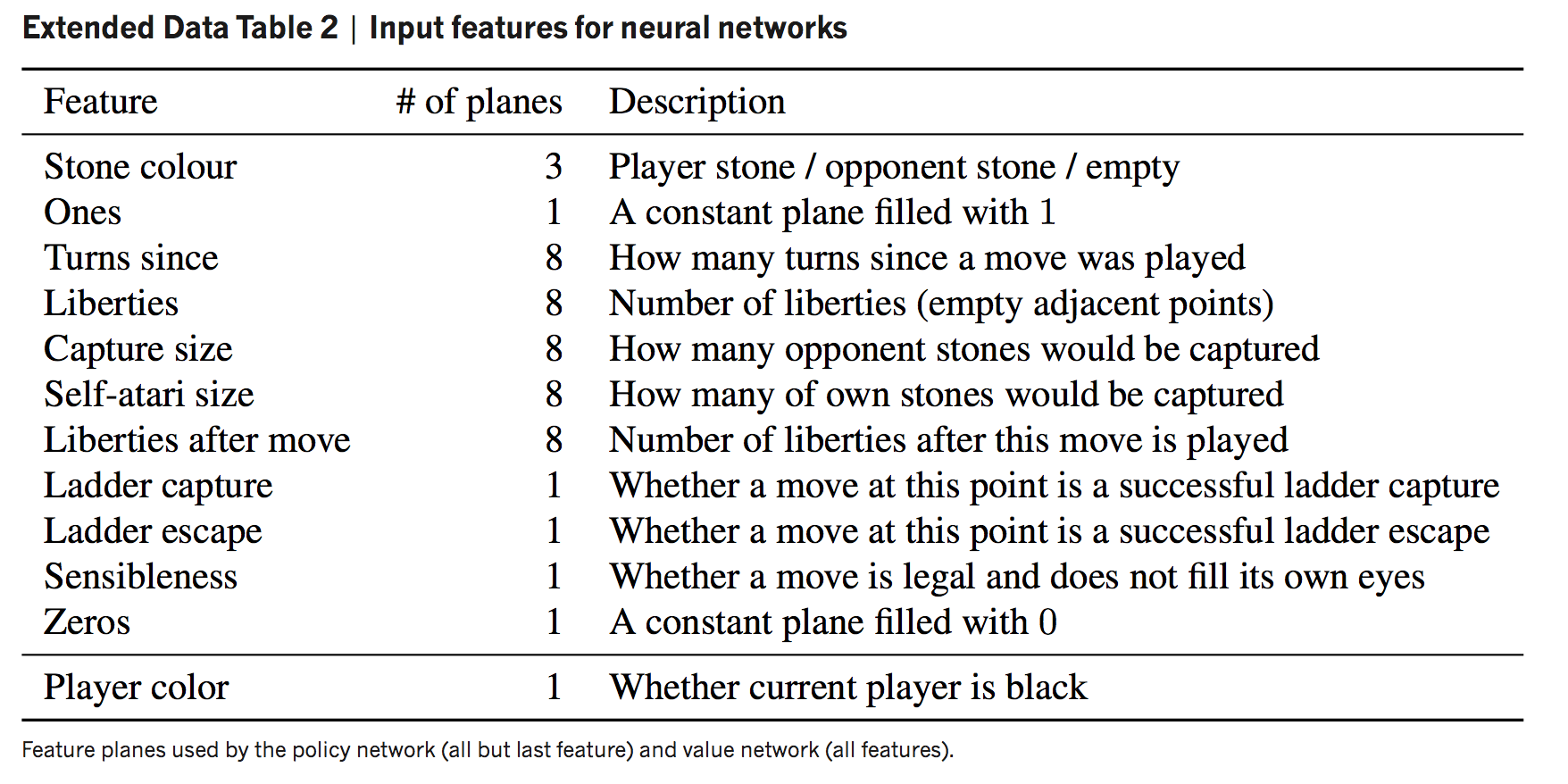
第一阶段通过预测人类专家落子位置训练出来的13层CNN策略网络,输入棋局的局面表示、游戏回合数等特征(完整特征在附录),输出每一个合法落子的概率分布。利用人类棋局作为训练样本,可以快速的降低预测误差。AlphaGO采用的是KGS GO server的3000万个对局局面,在使用完整特征的的条件下能够在测试集达到57.0%的预测准确率,仅使用局面图像和历史输入作为特征的策略网络可以达到55.7%,这说明人类的落子策略也并不难猜。
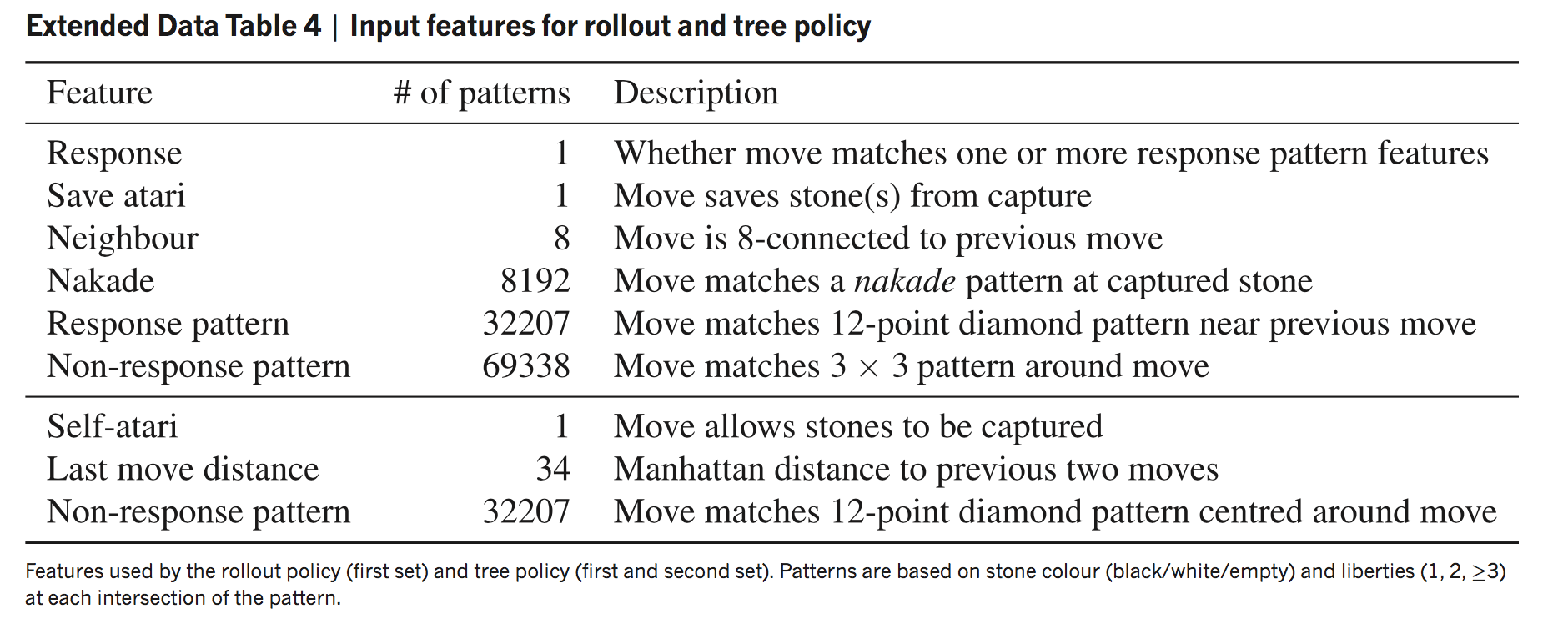
同时训练一个快速落子的策略网络(特征列表在附录),简单地基于一些模式通过softmax预测落子,在测试集的预测准确率只有24.2%,但是相比于的3毫秒,只需要2微秒。
Reinforcement learning of policy network
第二阶段使用增强学习的policy gradient的通过自我对弈方法训练更强的、全新的策略网络,的结构与一致。以为起点,使用当前的和随机之前某一次迭代过程中的(防止对当前策略过拟合)进行对弈,直到分出胜负。参数的更新公式:
其中,时间步,为对局结束时经历的步数,是在第步落子时获得的奖励,在对局结束时所获得的奖励。在围棋中,合理的奖励设置是胜利时为1,失败时为-1,其他任何一步的奖励都替换为最终的奖励,A和B对弈,最终A获胜时,将A的每一步落子奖励+1,失败时将每一步落子奖励-1。这会促使RL policy追求适合当前局面更能获胜的落子。
值得一提的是,RL Policy对SL Policy的胜率超过了80%,对Pachi的胜率超过了85%(Pachi是一个开源的围棋程序,使用蒙特卡洛搜索,每一步需要执行十万次模拟,在KGS上达到了业余二段的水平)。
Reinforcement learning of value network
最后阶段,训练评估局面的价值函数根据当前局面输出最终的期望结果。其定义为(3)
理想的情况是穷举所有局面以获得最优的,实际训练是使用最强的策略网络RL Policy 训练价值函数,近似的认为 。的网络结构与策略网络一致,只是输出变为一个简单的预测数字。使用梯度下降对进行更新:
幼稚的做法是对于每局比赛的每一个局面都用来作为训练样本,因为相邻的局面耦合程度非常高,这会导致严重的过拟合。论文中采用的做法是从3000万局自我对局中每一局选取一个局面进行训练,使得过拟合达到最小化。
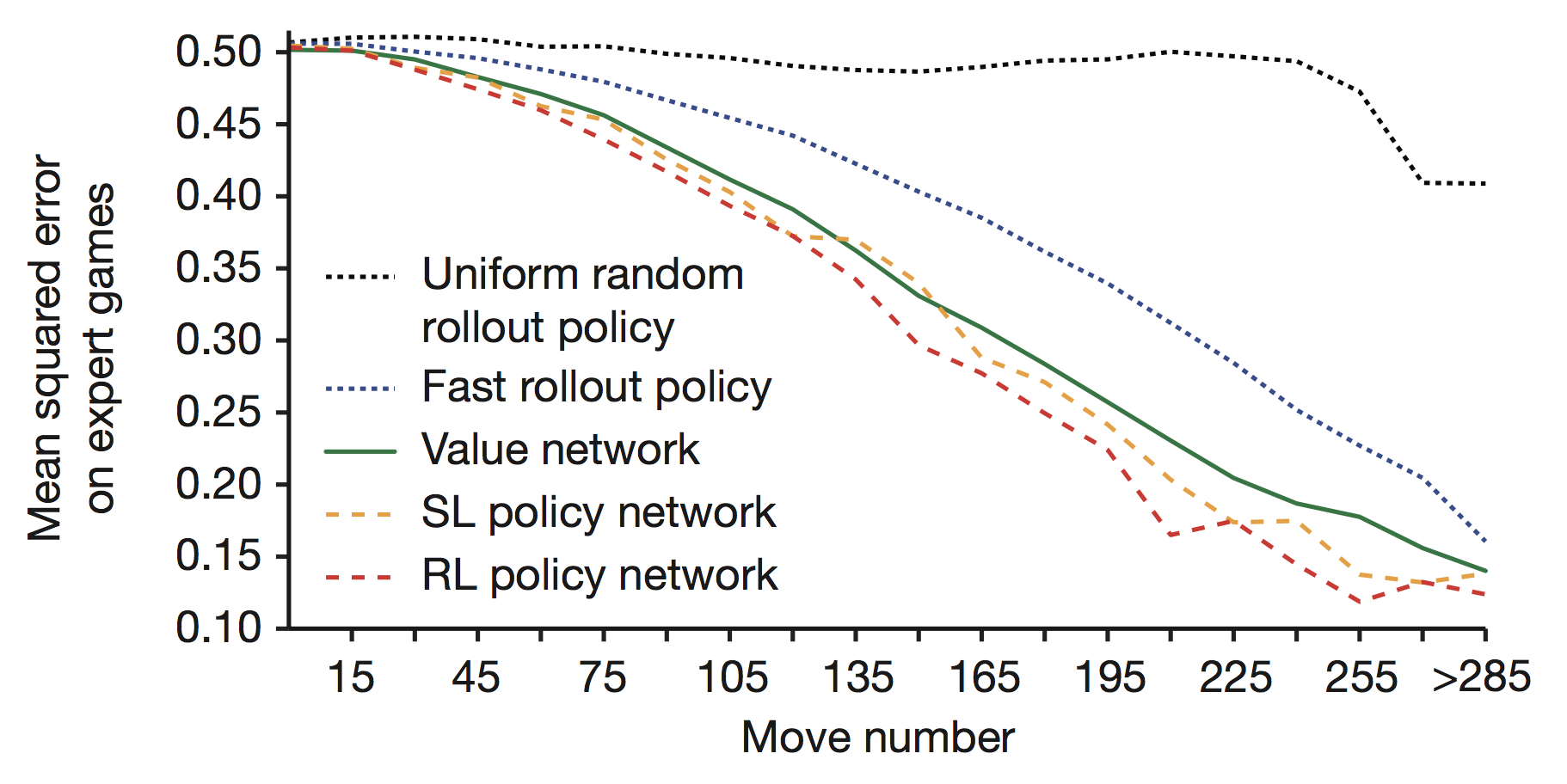
策略网络可以在很短的时间内评估当前局面,尽管策略网络同样可以通过多次模拟比赛以计算平均结果值估计当前局面,但需要大量的计算时间。
落子
MCTS是几乎所有围棋程序的核心组件,AlphaGO将策略网络和价值网络结合在MCTS中,MCTS的每个节点代表一个局面,每条边代表一个动作(落子),用表示。其中每一条边都存储三个变量:1.动作-价值函数(在状态下执行动作后对局面的评估值);2.当前边的访问次数;3.先验概率。
一个完整的MCTS包括四个步骤:Selection,Expansion,Evaluation,Backup。
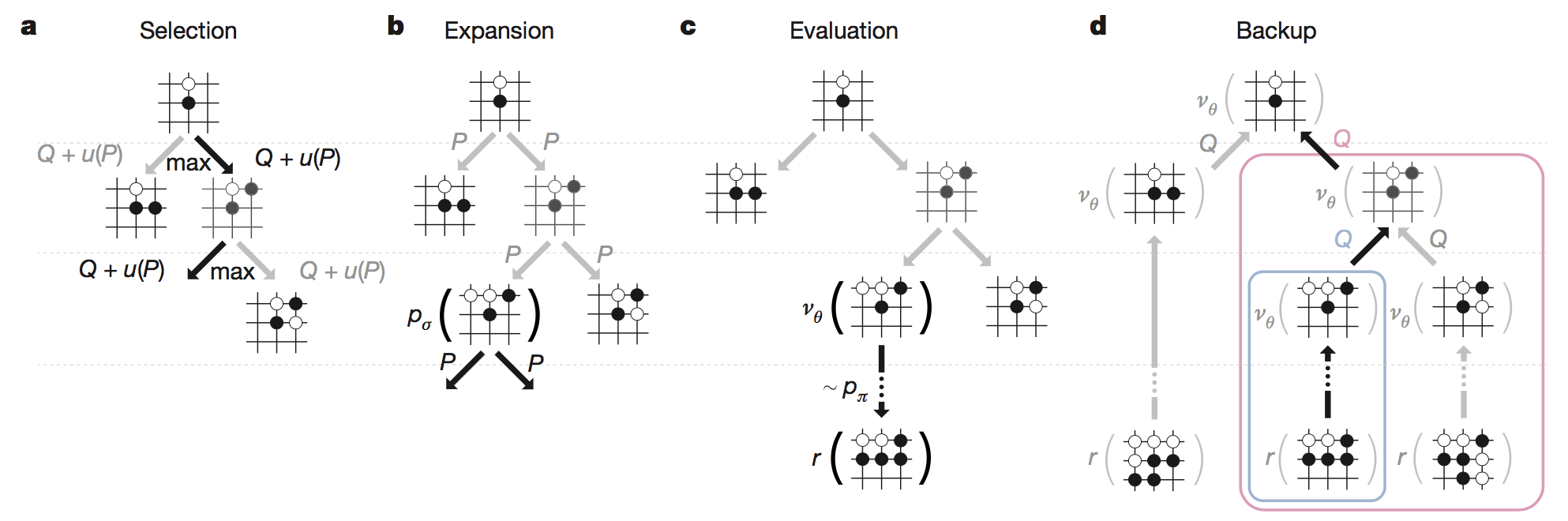
搜索过程会进行多次迭代,每次迭代在模拟出胜负后结束,在所有迭代结束后选取当前节点对应的最高的的边,采取落子动作,第次迭代完整过程如下:
从根节点(当前局面)开始,在每一个节点:
-
如果当前节是叶子节点,扩展叶子节点(Expansion):
-
对于所有合法的落子动作,使用SL policy初始化这条边的先验概率,并根据对应的落子设置子节点;
-
评估叶子节点同时用到了估值网络和快速落子网络,设当前时间步为,利用快速落子网络模拟到比赛结束,根据胜负得到,用于控制两者的贡献率
-
-
如果当前节点不是叶子节点,根据时间步t所处的状态节点选取最优落子动作
其中 与先验概率成正比,与访问次数成反比,这样做的目的是为了更多的探索性。
一旦完成模拟,就更新所有的和
(9)的做法是对多次迭代中多次遇到的时,计算Q(s,a)的平均值(蒙特卡洛思想)。表示在第i次迭代时访问过为1,否则为0。
使用SL policy做的效果要比RL policy好,论文中的解释是因为人类下棋时是带有对将来思考的,而自我学习得到的策略网络通常只针对当前局面选取最优的策略。但通过RL policy训练的仍然是强于SL policy的。
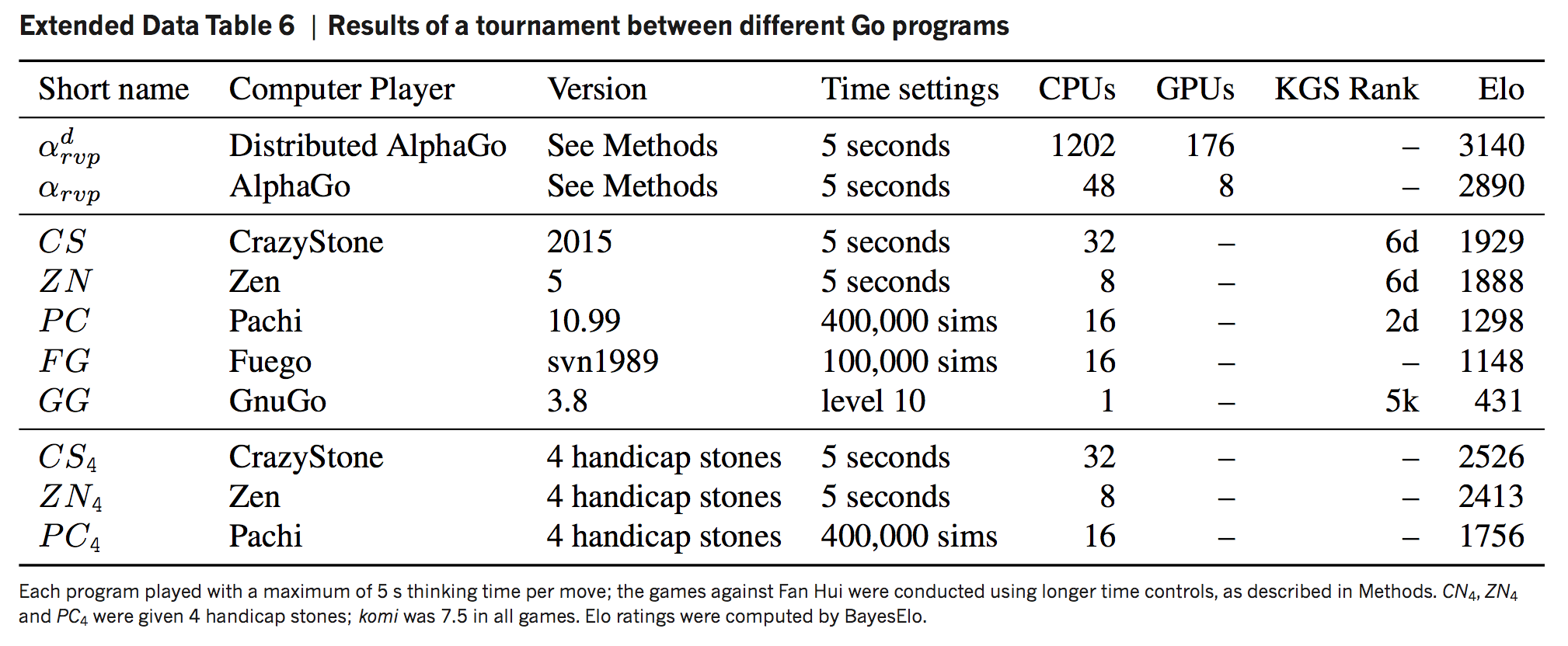
有意思的是,只使用估值网络对局面评估的效果还不如快速落子网络,田渊栋给出的猜测是在棋局一开始时,大家下的比较和气,估值网络就比较重要;在复杂的对杀情况中,通过快速走子估计盘面就比较重要了,内部评分最高的版本使用的就是0.5(附录中有各种不同版本的AlphaGO评分)。
另外,在叶子节点时并不是立刻展开,而是等访问次数到达40次时,这样可以避免产生太多分支,分散搜索的注意力。
结语
AlphaGO使用了较少的专业知识达到如此惊人的效果,具有一定的通用性,文末指出了AlphaGO对以下三种问题具有启发性:
-
有挑战的决策任务
-
具有无法穷举的巨大的搜索空间
-
难以直接使用策略函数和估值函数估计出最优策略
如果看到这里都明白的话,也许你也想实现一个自己的AlphaGO,那么你可以先采购单机版的AlphaGO所使用的硬件:48个CPU和8个GPU。
FAQ
-
为什么使用神经网络训练策略函数和价值函数?
因为棋盘局面太多,无法穷举出每一个局面state,因此使用神经网络根据一定特征来做value function approximation,而策略函数是基于state的,因此也需要神经网络的帮助。
-
在蒙特卡洛搜索中并没有提到对两个棋手的分别模拟,对方棋手的落子策略采用的是什么呢?
论文中没有提到使用时是对双方进行模拟,但这应该是肯定的。
-
为什么不直接使用RL policy下棋,而是这么麻烦的构造一棵MCTS?
正如文中所提到的,RL policy没有前瞻性,无法规划一系列的动作,它只选取当前局面最优的策略,这样的策略并不是全局最优的。
-
为什么在构造MCTS时,要增加探索性(exploration)?
假如你面前有两扇门A和B,你第一次打开了A得到了1点奖励,那么下一次你是去选择当前最优的A还是B?
附录
策略网络和估值网络完整的训练特征
快速落子网络特征
不同版本的AlphaGO评分